Šta je robots.txt fajl i kako da ga podesite na svom web sajtu?

Web robot (poznat i kao web crawler, web bot ili web spider) je softver koji automatski pretražuje web sajtove i stranice kako bi prikupio informacije o sadržaju na njima. Njegova osnovna svrha je da skenira sadržaj sa web-a kako bi indeksirao sadržaj za search engine, ali se koristi i u razne druge svrhe, kao što su prikupljanje podataka za analitiku, provera linkova ili nadgledanje promena na web sajtovima.
Bilo da želite da striktno definišete pristup vašem sajtu ili da radite na produkcionom sajtu bez pojavljivanja u Google pretrazi, robots.txt fajl obaveštava web robote o tome koje informacije mogu da prikupe.
U ovom tekstu ćemo objasniti kako da kreirate ovaj fajl direktno u svom cPanel nalogu.
Šta je robots.txt fajl?
Robots.txt je običan tekstualni fajl koji se nalazi u root folderu vašeg sajta i prati standard pod nazivom robots Exclusion Standard. Ovaj fajl se sastoji od jednog ili više pravila koja web robotima dozvoljavaju ili blokiraju pristup, ograničavajući ih na određenu putanju do fajla/foldera na sajtu. Podrazumevano, svi fajlovi su u potpunosti dozvoljeni za pretraživanje osim ako u robots.txt fajlu nije drugačije navedeno
Šta je Robots Exclusion Standard?
Robots Exclusion Standard (standard za isključenje robota) je protokol koji omogućava vlasnicima web sajtova da kontrolišu ponašanje web robota na njihovim sajtovima. Ovaj standard definiše pravila koja web roboti treba da slede prilikom indeksiranja i skeniranja web sajtova.
Glavni element Robots Exclusion Standarda je robots.txt fajl, koji se često naziva “robots.txt” ili “Robots Exclusion Protocol”.
Robots Exclusion Standard vam omogućava da:
- Odredite koje delove vašeg web sajta želite da web roboti indeksiraju, a koje ne
- Kontrolišete pristup određenim delovima sajta, na primer, osetljivim informacijama ili stranicama koje su još u izradi
- Ograničite učestalost indeksiranja, radi sprečavanja prekomernog opterećenja servera
Gde se nalazi robots.txt fajl?
Kako smo već rekli, robots.txt fajl se nalazi u root folderu vašeg web sajta. Na primer, www.nekisajt.rs bi imao robots.txt fajl na URL-u na www.nekisajt.rs/robots.txt.
Robots.txt fajl je jedan od prvih aspekata koji se analizira od strane web robota. Važno je napomenuti da vaš sajt može imati samo jedan robots.txt fajl. Ovaj fajl se implementira na jednoj ili više stranica ili celom sajtu kako bi se search engine-ima onemogućilo da pokupe detalje o vašem sajtu.
U ovom tekstu ćemo objasniti kako da kreirate i postavite robots.txt fajl i ujedno objasniti način na koji da postavite pravila, kako biste onemogućili određene botove da pristupaju vašem web sajtu.
Kako da postavite robots.txt fajl
- Kreirajte robots.txt fajl
Da biste postavili robots.txt fajl, pre svega je potrebno da imate pristup root folderu vašeg sajta.
Najvažniji deo datoteke je njeno kreiranje i lokacija. Možete da koristite bilo koji tekst editor za kreiranje robots.txt fajla. Kako smo već pomenuli, robots.txt fajl se može naći na sledećim lokacijama:
- U root folderu vašeg sajta (npr. www.nekisajt.rs/robots.txt)
- Vašim poddomenima (npr. nekastranica.nekisajt.rs/robots.txt)
- Nespecifičnim portovima (npr. www.nekisajt.rs:881/robots.txt)
Napomena: robots.txt fajl se ne sme postavljati u poddirektorijum vašeg domena (www.nekisajt.rs/nekastranica/robots.txt).
Nakon kreiranja je potrebno da proverite da li je vaš robots.txt. fajl UTF-8 kodiran tekstualni fajl. Google i drugi popularni search engine web roboti mogu ignorisati karaktere izvan opsega UTF-8, što potencijalno čini vaša pravila u ovom fajlu nevažećim.
2. Postavite vaš robots.txt user-agent
Sledeći korak u kreiranju robots.txt fajla je postavljanje user-agent-a. Svaki user-agent se odnosi na određeni web robot ili search engine koje želite da dozvolite ili blokirate. Ispod je prikazana tabela najpoznatijih user-agent-a i sa njima povezanih search engine-a
| User-agent | Search engine |
| GoogleBot | Google Search |
| BingBot | Bing Search |
| Slurp Bot | Yahoo Search |
| DuckDuckBot | Duck Duck Go Search |
| Baiduspider | Baidu Search Engine |
| YandexBot | Yandex Search Engine |
| Sogou web | Sogou Search Engine |
| Facebot | Exalead Search Engine |
| Exabot | Facebook (Meta) |
| la_archiver | Amazon Alexa Internet Ranking |
Postoje tri različita načina za uspostavljanje user-agent-a unutar vašeg robots.txt fajla.
Kreiranje jednog user-agent-a
Sintaksa koju koristite za postavljanje user-agent–a je sledeća: User-agent: NazivBot-a.
Na primeru ispod, DuckDuckBot je jedini koji je postavljen.
User-agent: DuckDuckBotDodavanje user-agent-a
Ako treba da dodate više od jednog user-agent-a, pratite isti proces kao što ste uradili u prethodnom primeru, uz ubacivanje naziva dodatnog user-agent-a. U ovom primeru, korisićemo Facebot.
User-agent: DuckDuckBot
User-agent: FacebotPostavljanje svih botova kao user-agent
Da biste blokirali ili odobrili sve botove ili search engine, zamenite naziv bota zvezdicom (*).
User-agent: *3. Postavite pravila za vaš robots.txt fajl
Robots.txt fajl se čita u grupama. Grupa će navesti koji je user-agent i imati jedno pravilo ili direktivu koja će pokazati kojima fajlovima ili direktorijumima user-agent može ili ne može pristupiti.
Evo direktiva koje se koriste:
Kada kreirate robots.txt fajl, koristite različite direktive kako biste kontrolisali ponašanje web robota na vašem sajtu. Evo detaljnog objašnjenja za svaku od ovih direktiva:
Disallow: Ova direktiva se koristi da biste web robotima zabranili pristup određenim delovima vašeg sajta. To znači da web roboti ne smeju indeksirati ili pristupiti sadržaju koji je obuhvaćen ovom direktivom. Na primer, ako želite da zabranite web robotima pristup direktorijumu sa fajlovima za administraciju (npr. /admin/), možete koristiti sledeći format:
Disallow: /admin/Ovo će sprečiti web robote da pristupe bilo kojem sadržaju koji se nalazi u /admin/ direktorijumu.
Allow: Ova direktiva se koristi da biste dozvolili pristup određenim delovima vašeg sajta web robotima. Ovo se obično koristi kada želite da prekršite opštu zabranu koja je navedena u prethodnoj direktivi Disallow. Na primer, ako želite da dozvolite pristup jednom određenom direktorijumu unutar direktorijuma koji ste inače zabranili, možete koristiti sledeći format:
Allow: /photos/Ovo će dozvoliti web robotima pristup sadržaju koji se nalazi u /photos/ direktorijumu.
Sitemap: Ova opcionalna direktiva se koristi da biste naveli lokaciju XML sitemap datoteke za vaš sajt. Sitemap je fajl koji sadrži listu svih URL-ova na vašem sajtu koji su važni za indeksiranje. Navedeni sitemap pomaže web robotima da bolje razumeju strukturu vašeg sajta i da efikasnije indeksiraju njegov sadržaj. Na primer, ako imate sitemap fajl nazvan “sitemap.xml” na svom sajtu, možete koristiti sledeći format:
https://www.example.com/sitemap.xmlOvo će obavestiti web robote da pogledaju sitemap fajl kako bi pronašli sve relevantne URL-ove na vašem sajtu.
Korišćenje ovih direktiva omogućava vam da precizno kontrolišete kako web roboti indeksiraju i pristupaju sadržaju na vašem sajtu, što vam omogućava da poboljšate performanse vašeg sajta u pretraživačima i bolje upravljate njegovim sadržajem.
Web roboti obrađuju grupe od vrha prema dnu. Kao što je već pomenuto, oni pristupaju bilo kojoj stranici ili direktorijumu koji nije eksplicitno postavljen da se zabrani. Stoga, dodajte Disallow: / ispod informacija o user-agentu u svakoj grupi kako biste blokirali te konkretne user-agente od pretraživanja vašeg web sajta.
User-agent: DuckDuckBot
Disallow: /
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
User-agent: *
Disallow: /Da biste blokirali određeni poddomen od svih web robota, dodajte kosu crtu i pun URL poddomena u vašu zabranu.
User-agent: *
Disallow: /https://page.nekisajt.rs/robots.txtAko želite da blokirate direktorijum, pratite isti proces dodavanjem kose crte i imena vašeg direktorijuma, ali zatim završite još jednom kosom crtom.
User-agent: *
Disallow: /images/Na kraju, ako želite da svi search engine-i prikupljaju informacije o svim stranicama vašeg sajta, možete kreirati ili pravilo za dozvolu ili pravilo za zabranu, ali budite sigurni da dodate kosu crtu kada koristite pravilo za dozvolu. Primeri oba pravila su prikazani ispod.
User-agent: *
Allow: /
User-agent: *
Disallow:4. Postavite vaš robots.txt fajl
Web sajtovi ne dolaze podrazumevano sa robots.txt fajlom jer to nije obavezno da bi sajt funkcionisao. Kada odlučite da kreirate ovaj fajl, postavite ga u root folder vašeg sajta.
Postavljanje zavisi od strukture fajlova vašeg sajta i okruženja u kom se nalazi vaš hosting server.
Mi ćemo ovde prikazati primer kako da postavite robots.txt fajl preko svog cPanel naloga.
Za početak se ulogujte na svoj cPanel nalog i u dashboard-u pronađite sekciju pod nazivom Files.
Sada kliknite na ikonicu pod nazivom File Manager i otvoriće vam se prozor kao na slici ispod.
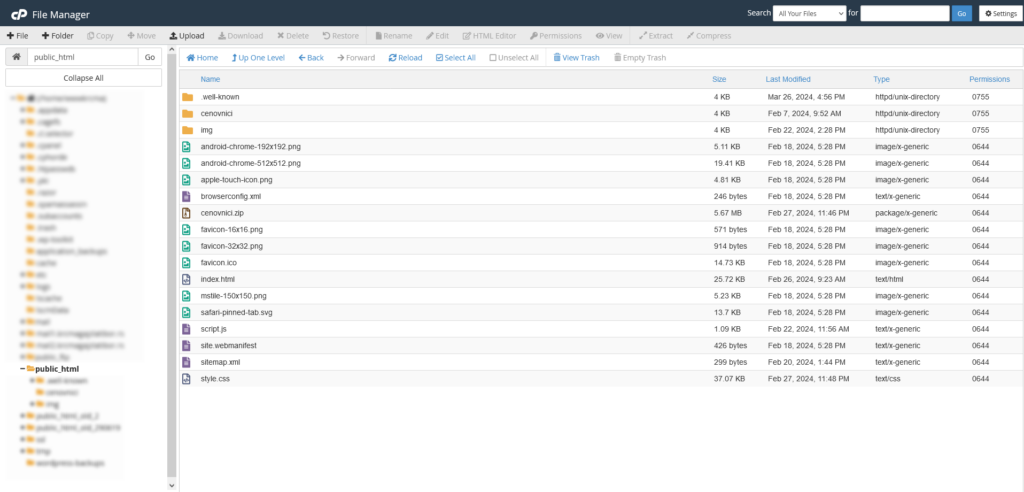
U stablu sa leve strane prozora pronađite folder u kojem je smešten vaš web sajt. To je najčešće public_html. Kada kliknete na taj folder, u prozoru sa desne strane će se prikazati sadržaj tog foldera. Ako do sada niste upload-ovali robots.txt fajl, onda ga nećete pronaći među ostalim fajlovima.
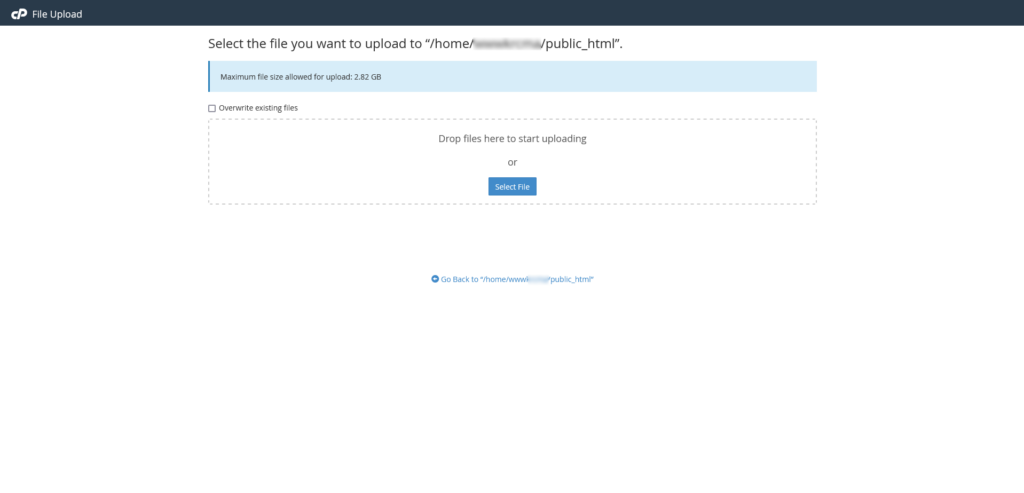
Sada možete da upload-ujete svoj robots.txt fajl u folder svog web sajta. U našem slučaju root folder je public_html, pa ćemo ga upload-ovati u taj folder.
Kliknite na dugme Upload u tool bar-u u vrhu prozora i zatim izaberite fajl koji ste kreirali. Izaberite fajl i on će biti automatski upload-ovan na vaš web sajt.
Sada ćete u prozoru sa desne strane videti svoj robots.txt fajl među ostalim fajlovima.
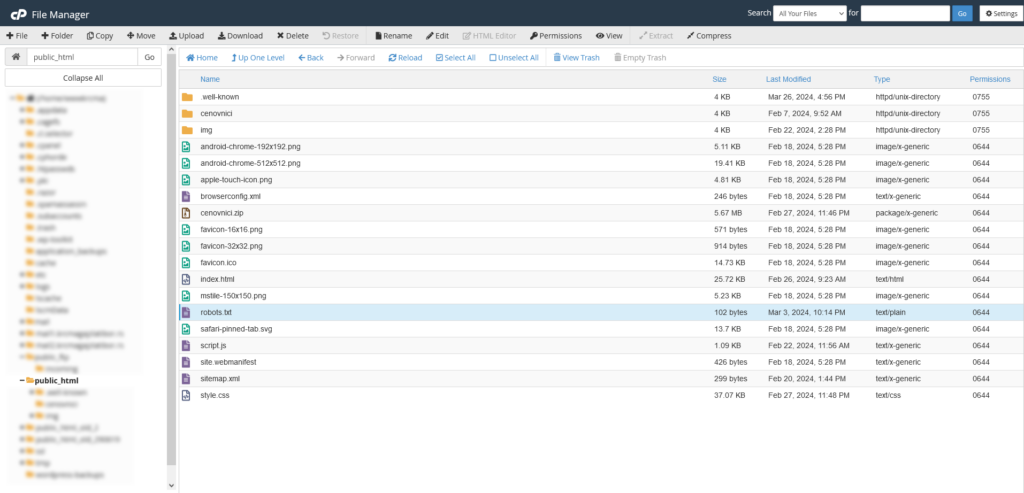
5. Proverite da vaš robots.txt fajl ispravno funkcioniše
Postoji nekoliko načina da testirate i proverite da li vaš fajl ispravno funkcioniše. Jedan od najjednostavnijih načina jeste da proverite da li se nalazi na ispravnoj lokaciji je da u address bar svog browsera unesete naziv sajta, a zatim /robots.txt. Na primer: www.nekisajt.rs/robots.txt.
Ukoliko ste ispravno postavili robots.txt fajl, na tom linku će vam se otvoriti sadržaj tog fajla.
Takođe, možete ga testirati na određene user-agente pomoću sledećih alata:
- Merkle-ov Validator and TestingTool
- Logeix-ov robots.txt Testing Tool
- Tame the Bots-ov Testing Tool
Zaključak
U ovom tekstu smo objasnili šta je robots.txt fajl i prošli smo kroz proces kreiranja ovog fajla. Kao što ste videli ovi koraci su jednostavni i mogu vam uštedeti vreme i glavobolje od pretraživanja sadržaja na vašem sajtu bez vaše dozvole.
Ukoliko ste već upoznati sa ovom temom, možda će vam biti interesantno da pročitate koji su to najčešći problemi sa robots.txt fajlom i kako da ih rešite.
Takođe, ako vas zanima kako da podesite robots.txt fajl za WordPress sajt, pročitajte naše tekstove ALL IN ONE SEO plugin – podešavanja za bolji SEO (2.deo) i Kako da blokirate loše botove od pristupa vašem web-sajtu – All in one SEO plugin (3.deo)
Nenad Mihajlović