ALL IN ONE SEO plugin – podešavanja za bolji SEO (2.deo) – Robots.txt

U prošlom tekstu na temu podešavanja ALL IN ONE SEO plugin-a za bolji SEO (koji možete pročitati ovde),pisali smo na temu podešavanja na nivou opštih podešavanja (General Settings).
U ovom tekstu (2. deo) ćemo objasniti kako da izvršite neka od podešavanja na nivou Feature Manager.
S obzirom da na ovom nivou ima više podešavanja, danas ćemo pisati konkretno o tome kako da podesite vaš veb-sajt da ispravno prihvata ili odbija indeksiranje od strane robota (crawler-a), koje inače koristi svaka platforma za pretraživanje i indeksiranje sadržaja (Google, Bing…itd).
Zašto je to važno?
Za početak ćemo kratko objasniti zašto je zapravo važno da naš veb-sajt podesimo tako da imamo kontrolu nad tim šta će roboti indeksirati.
Ako ste tek napravili i pokrenuli vaš veb-sajt, registrovali ga na Google Search Console-i, vrlo je verovatno da vam ova vrsta kontrole neće odmah biti potrebna. Roboti će indeksirati sve vaše stranice, kojih u početku obično nema puno i to je sasvim u redu.
Vremenom vaš veb-sajt polako postaje sve veći, možda ćete dodati neke nove strane, a gotovo sigurno ćete dodati i mnogo novog sadržaja (tekstova, fotografija…). Negde tada otprilike počinje da bude važno koje strane i sadržaji će biti indeksirani od strane Google-a.
Verovatno se već pitate zašto bi to bilo važno.
Pokušaćemo ovde ukratko da damo odgovor na to pitanje
Robots.txt fajl
Da biste uopšte mogli da imate kontrolu nad tim šta će roboti moći da indeksiraju, morate kreirati robots.txt fajl. Ovaj fajl predstavlja neku vrstu uputstva za robote uz pomoć kojeg oni “znaju” koje strane ili sadržaji su im dozvoljeni za indeskiranje, a koji nisu. Rekli bismo neka vrsta vodiča za robote kako da se ponašaju na vašem veb-sajtu.
Ukoliko robots.txt file nije kreiran, roboti će uvek indeksirati sav sadržaj koji mogu da indeksiraju.
Verovatno se već pitate: Pa šta je loše u tome što če ceo sadržaj mog sajta biti indeksiran? Zar to nije upravo ono što je dobro za moj sajt?
Odgovor je: Pa nije nužno loše, ali kod sajtova sa više stranica i sadržaja ovo može da bude problem.
Kako to radi?
Roboti su napravljeni tako da u svakoj sesiji mogu indeksirati samo određeni broj veb-stranica i sadržaja. Ukoliko tom kvotom nisu obuhvaćene sve vaše stranice i sadržaji , robot će u sledećoj sesiji morati da nastavi sa indeksiranjem preostalih stranica i sadržaja, što u krajnjoj instanci ima za posledicu sporije indeksiranje vašeg sajta.
Kao što smo do sada već zaključili, sporije i lošije indeksiranje utiče i na vaš SEO skor koji vam dodeljuje Google. Sve to zajedno predstavlja lošu stvar za vaš veb-sajt, a vi ne želite da vaš biznis pati zbog toga.
Zato smo mi tu da vam pomognemo da pravilno podesite robots.txt fajl, tako da u susretu sa robotima njima da jasna pravila koje strane i sadržaje da indeksiraju, a koje ne.
Kako to postići?
Ovo možete postići tako što ćete recimo robots.txt fajl podesiti tako da ne registruju na primer WordPress admin stranice, ili fajlove koji imaju veze sa plugin-ima i temama koje ste instalirali na vašem sajtu. Nema puno smisla da ostavite dozvoljenim indeksiranje sadržaja koji ne pripada originalno vašem veb-sajtu i ne odražava ono što predstavlja samo vaš biznis.
Robots.txt fajl se nalazi u root-u index (home) foldera na vašem veb-sajtu. Za jednostavan uvid u sadržaj vašeg robots.txt fajla dovoljno je da u search bar pretraživača unesete naziv vašeg domena praćen sa /robots.txt i pojaviće se sadržaj vašeg robots.txt fajla onako kako je on trenutno podešen. Verovatno je da ćete videti nešto slično ovome:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Ako ste pritom već kreirali i sitemap.xml fajl, onda će sadržaj robots.txt fajla pratiti i naziv vaše xml mape sajta:
Sitemap: https://www.vašdomen/sitemap.xml
Kako onda izvršiti podešavanja?
Pošto velika većina vlasnika veb-sajta nije baš upućena u ove tehničke detalje, najjednostavnije je da se to uradi uz pomoć plugin-a koji sve može da odradi umesto vas.
Ipak, važno je da znate na koji način ovo da uradite i na šta je potrebno da obratite pažnju.
Postoji veliki broj plugin-ova koji mogu poslužiti ovoj nameni, ali se mi danas bavimo ovde ALL IN ONE SEO plugin-om, koji takođe ima opciju za podešavanje robots.txt fajla.
A pošto je bilo dosta priče – vreme je da konačno krenemo u neku konkretnu akciju.
Uvod u podešavanje robots.txt fajla
U našem prošlonedeljnom tekstu (koji možete pročitati ovde), naučili smo kako izgleda ALL IN ONE SEO interfejs. U principu je vrlo jednostavan i intuitivan, pa se nećemo vraćati na tu temu.
Krenućemo od opcije Feature Manager (Slika 1).
Kliknite na Feature Manager i otvoriće se prozor kao na slici 2.
Skrolujte ispod do sekcije pod nazivom Feature Manager i pronađite modul pod nazivom Robots.txt (Slika 3)
Kliknite na dugme Activate da biste aktivirali ovaj modul. Odmah po aktivaciji u meniju ALL IN ONE SEO plugin-a pojaviće se nova opcija pod nazivom Robots.txt (Slika 4)
Odaberite ovu opciju iz menija i kliknite na nju. Sada skrolujte do sekcije Create a Robots.txt File (Slika 5)
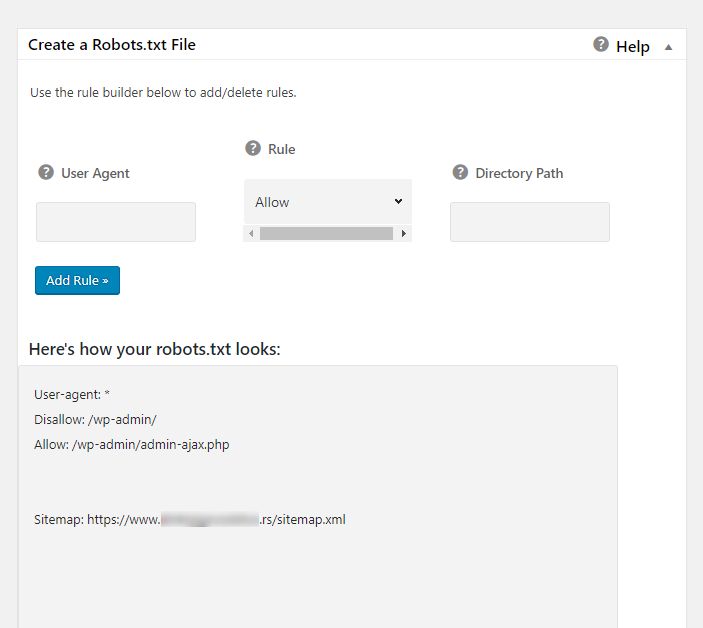
U ovoj sekciji sada možemo definisati koje robote želimo da pustimo da posete/indeksiraju stranice i sadržaj našeg veb-sajta, a koje ne želimo. Moguće je izabrati sledeće opcije:
- (User Agent) tačno ime robota (bota)
- (Rule) pravilo koje definišete (allow/disallow) – odobri/ne dozvoli
- (Directory Path) putanja za koju želite da dozvolite ili ne dozvolite pristup
User agent
Svaki robot ima svoje zvanično ime, a listu ovih imena možete naći na nekoliko veb-sajtova. ALL IN ONE SEO plugin preporučuje listu koju možete pronaći na adresi https://www.robotstxt.org/db.html , ali mi smatramo da ta lista nije baš idealan izbor, pa smo sastavili našu listu baziranu na osnovu našeg iskustva i iz dobre prakse kreiranja robots.txt fajlova. Nju ćemo i primeniti u kreiranju našeg fajla u ovom tekstu.
Rule
Kao što i samo ime kaže, ovom opcijom možete definisati pravilo koje želite da robot sledi prilikom posete vašem veb-sajtu. Moguće su opcije allow (dozvoli) i disallow (ne dozvoli).
Directory path
Ovde definišete neku specifičnu putanju na vašem veb-sajtu za koju želite da kreirate neko pravilo. Na primer, želite da dozvolite pristup samo stranama Naslovna, O nama i Usluge. Ili želite da ne dozvolite pristup strani Cenovnik. Direktorijum (putanja) se unosi na standardni način, korišćenjem znaka / i imenom direktorijuma iza tog znaka (na primer /Cenovnik). Ukoliko ostavite samo znak / robot će podrazumevati da ima pristup svim fajlovima i stranicama na vašem veb-sajtu.
Podešavanje Robots.txt fajla
U polje User agent unosimo nazive odabranih botova. Mi smo za ovu priliku odabrali one koji su legalni i koji su već poznati po pridržavanju definisanih standarda prilikom crawling-a preko veb-sajtova.
To su:
Googlebot, Bingbot, baiduspider, Facebot, msnbot, Naverbot, seznambot, Slurp, teoma, Twitterbot, Yandex, Yeti
Nećemo se ovde detaljnije baviti kome koji robot pripada, ali neke od njih možete i sami lako prepoznati po nazivu. Ukoliko vas zanima koji od navedenih robota pripada kojoj platformi za pretragu, pišite nam u komentaru i mi ćemo vam rado poslati odgovor.
Za sada je važno da znate kako da ih unesete u polje User agent.
- kopirajte ovu listu u polje User agent (ili upišite jedan po jedan sa zarezom između)
- u polju Rule odaberite opciju Allow
- u polje Directory path unesite samo znak / (Slika 6)
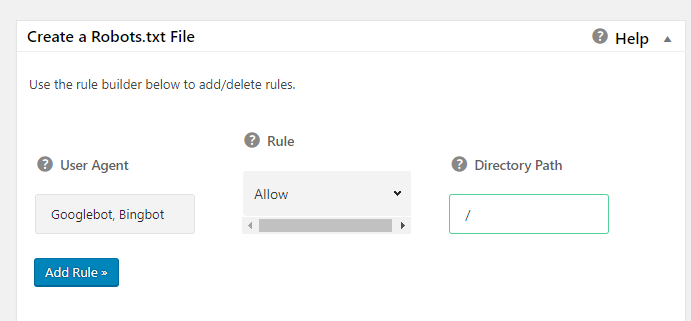
Nakon što uneste sve navedeno kliknite na polje Add rule.
Ispod će se pojaviti definisano pravilo (Slika 7).
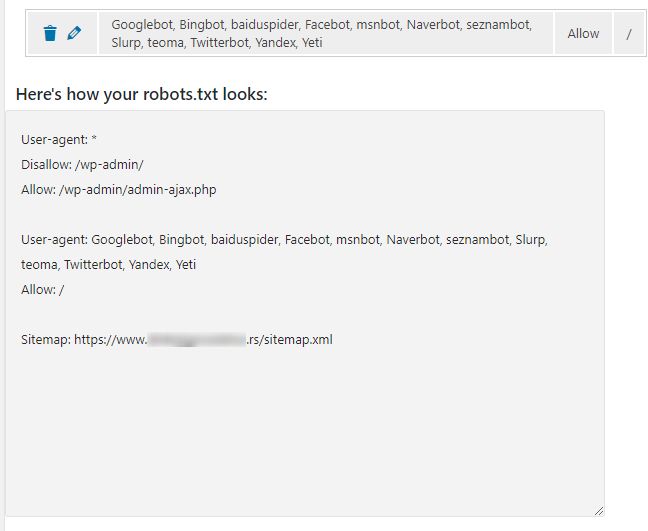
Ovim ste za sve navedene robote definisali pravilo da mogu da prelaze preko svih vaših veb stranica i direktorijuma na veb-sajtu. S obzirom da je podrazumevano podešavanje pre ovoga bilo
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
znači da nijednom robotu nije dozvoljen pristup putanji wp-admin, ali da istovremeno svim robotima dozvoljen pristup samo admin-ajax.php fajlu koji se nalazi u direktorijumu wp-admin.
Drugim rečima, na podrazumevano podešavanje robot.txt fajla dodali ste vaše pravilo kojim ste eksplicitno dozvolili da samo određeni, dobro poznati i legalni roboti (botovi), imaju pristup celokupnom sadržaju vašeg veb-sajta.
Ovim ste konačno na vašem veb-sajtu podesili robots.txt fajl i tako ga optimizovali da prilikom crawling sesija robota bude što manje problema u čitanju i indeksiranju, što za cilj ima i bolji ukupan skoring kod platformi za pretraživanje sadržaja kojima smo omogućili pristup.
U sledećem tekstu ćemo objasniti kako da dodatno optimizujete veb sajt blokiranjem takozvanih loših botova (Bad Bots), što bi u neku ruku bio logičan nastavak današnjeg teksta.
Do tada uživajte i budite nam veseli!
Nenad Mihajlović
November 19th, 2020 at 10:03 (#)
Odlično objašnjeno, bravo.
November 23rd, 2020 at 02:11 (#)
Hvala, Ivanka!